
یک روش پرامپتینگ جدید به نام "زنجیره تفکر برجسته" (HoT) به مدلهای زبانی بزرگ کمک میکند تا استدلال خود را بهتر توضیح دهند و پاسخهای آنها را برای انسانها آسانتر تأیید کنند.
این رویکرد در دو مرحله کار میکند: ابتدا، هوش مصنوعی سوال اصلی را بازنویسی میکند و حقایق مهم را با استفاده از تگهای XML علامتگذاری میکند. سپس، پاسخی تولید میکند که به این حقایق برجسته ارجاع میدهد و ارتباط روشنی بین سوال و پاسخ ایجاد میکند.
به گفته محققان، این رویکرد ساختاریافته، مدلها را مجبور میکند تا با دقت بیشتری حقایق ارائه شده را در نظر بگیرند، که ممکن است توهمات را کاهش دهد. برجستهسازیهای کدگذاری شده با رنگ نیز باعث میشود که انسانها بتوانند سریعتر استدلال هوش مصنوعی را تأیید کنند.

تیم تحقیقاتی از 15 جفت پرسش و پاسخ حاشیهنویسی شده توسط انسان برای آموزش مدلهای هوش مصنوعی استفاده کردند تا به طور مستقل از طریق پرامپتینگ، برجستهسازیها را تولید کنند. آزمایشها نشان میدهد که HoT دقت هوش مصنوعی را در وظایف مختلف بهبود میبخشد. در بهترین حالت، این تکنیک به بهبودهایی تا 15 درصد، بسته به مدل و معیار، دست یافت.
در مقایسه با روش سنتی زنجیره تفکر (CoT) که برای آموزش مدلهای استدلال فعلی مانند OpenAI o1 استفاده میشود، HoT دقت را برای وظایف محاسباتی 1.6 درصد، برای پرسش و پاسخ 2.58 درصد و برای استدلال منطقی 2.53 درصد افزایش داد.
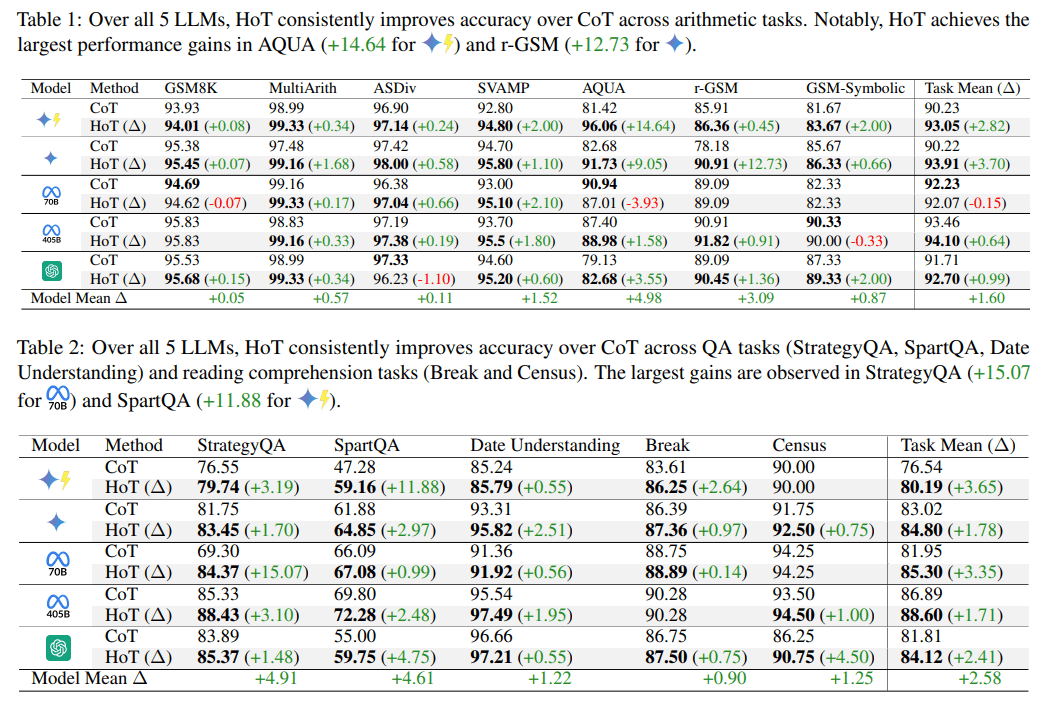
محققان HoT را در پنج مدل هوش مصنوعی آزمایش کردند: GPT-4o، Gemini-1.5-Pro، Gemini-1.5-Flash، Llama-3.1-70B و Llama-3.1-405B. آنها 17 نوع وظیفه مختلف را که شامل محاسبات، درک مطلب و تفکر منطقی بود، ارزیابی کردند.
مدلهای استدلالی در آزمایشها سود کمی از HoT نشان دادند یا اصلاً سودی نداشتند و در برخی موارد عملکرد بدتری داشتند، به طوری که Deepseek-R1 در واقع کمی کاهش عملکرد نشان داد. محققان این امر را به رویکرد پرامپتینگ مبتنی بر مثال نسبت میدهند که میتواند منجر به نتایج ضعیفتری با مدلهای استدلال شود.
نتایج متفاوت برای تأیید انسانی
آزمایشکنندگان انسانی وظایف تأیید را با پاسخهای برجسته شده 25 درصد سریعتر انجام دادند. با این حال، برجستهسازی تأثیر غیرمنتظرهای بر اعتماد داشت: کاربران بیشتر احتمال داشت که پاسخهای هوش مصنوعی را بپذیرند، حتی پاسخهای نادرست.
با برجستهسازی، انسانها پاسخهای دقیق را در 84.5 درصد مواقع به درستی شناسایی کردند، در حالی که بدون برجستهسازی این رقم 78.8 درصد بود. با این حال، توانایی آنها برای تشخیص پاسخهای اشتباه از 72.2 درصد به 54.8 درصد کاهش یافت. آزمایشهایی که از مدلهای هوش مصنوعی به عنوان تأییدکننده استفاده میکردند، هیچ بهبود واضحی را نشان ندادند.

محققان همچنان به پتانسیل HoT برای شفافتر و قابل فهمتر کردن سیستمهای هوش مصنوعی خوشبین هستند، اگرچه اذعان میکنند که تحقیقات بیشتری در مورد چگونگی تأثیر برجستهسازی بر اعتماد کاربران مورد نیاز است.
این روش همچنین دارای محدودیتهای فنی است. مدلهای کوچکتر مانند Llama-3.1-8B و Qwen-2.5-Coder-32B برای پیروی از دستورالعملهای برچسبگذاری مشکل دارند و اغلب نتایج را به اشتباه برچسبگذاری میکنند یا به سادگی مثالها را تکرار میکنند. این تحقیق همچنین نشان داد که انتقال برچسبها به عبارات تصادفی به طور قابل توجهی بر دقت تأثیر میگذارد و اهمیت برچسبگذاری مداوم بین سوالات و پاسخها را برجسته میکند.
با نگاهی به آینده، این تیم قصد دارد مدلهای هوش مصنوعی را آموزش دهد تا پاسخهای HoT را مستقیماً تولید کنند، نه اینکه از مثالهای پرامپت استفاده کنند، که میتواند این روش را مؤثرتر و کاربردیتر کند.
مقاله پژوهشی در سرور پیشچاپ arXiv و در صفحه پروژه موجود است. محققان کد و دادههای خود را در Github در دسترس قرار دادهاند.